The process models are based on various software development phases whereas the capability models have an entirely different basis of development. They are based upon the capabilities of software. It was developed by Software Engineering Institute (SEI). In this model, significant emphasis is given to the techniques to improve the “software quality” and “process maturity”. In this model a strategy for improving Software process is devised. It is not concerned which life cycle mode is followed for development. SEI has laid guidelines regarding the capabilities an organization should have to reach different levels of process maturity. This approach evaluates the global effectiveness of a software company.
Maturity Levels
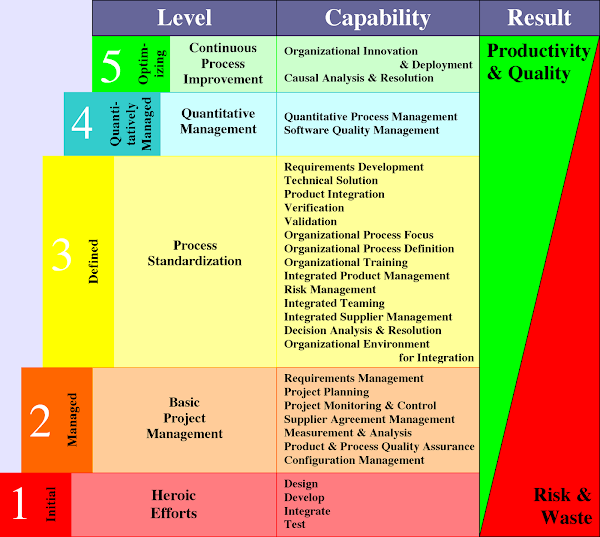
It defines five maturity levels as described below. Different organizations are certified for different levels based on the processes they follow.
Level 1 (Initial): At this maturity level, software is developed an ad hoc basis and no strategic approach is used for its development. The success of developed software entirely depends upon the skills of the team members. As no sound engineering approach is followed, the time and cost of the project are not critical issues. In Maturity Level 1 organizations, the software process is unpredictable, because if the developing team changes, the process will change. The testing of software is also very simple and accurate predictions regarding software quality are not possible.
SEI’s assessment indicates that the vast majority of software organizations are Level 1 organizations.
Level 2 (Repeatable): The organization satisfies all the requirements of level-1. At this level, basic project management policies and related procedures are established.
The institutions achieving this maturity level learn with experience of earlier projects and reutilize the successful practices in on-going projects. The effective process can be characterized as practiced, documented, implemented and trained. In this maturity level, the manager provides quick solutions to the problem encountered in software development and corrective action is immediately taken. Hence, the process of development is much disciplined in this maturity level. Thus, without measurement, sufficiently realistic estimates regarding cost, schedules and functionality are performed. The organizations of this maturity level have installed basic management controls.
Level 3 (Defined): The organization satisfies all the requirements of level-2. At this maturity level, the software development processes are well defined, managed and documented. Training is imparted to staff to gain the required knowledge. The standard practices are simply tailored to create new projects.
Level 4 (Managed): The organization satisfies all the requirements of level-3. At this level quantitative standards are set for software products and processes. The project analysis is done at integrated organizational level and collective database is created.
The performance is measured at integrated organization level. The Software development is performed with well defined instruments. The organization’s capability at Level 4 is “predictable” because projects control their products and processes to ensure their performance within quantitatively specified limits. The quality of software is high.
Level 5 (Optimizing): The organization satisfies all the requirements of level-4. This is last level. The organization at this maturity level is considered almost perfect. At this level, the entire organization continuously works for process improvement with the help of quantitative feedback obtained from lower level. The organization analyses its weakness and takes required corrective steps proactively to prevent the errors.
Based on the cost benefit analysis of new technologies, the organization changes their Software development processes.
Key Process Areas
The SEI has associated key process areas (KPAs) with each maturity level. The KPA is an indicative measurement of goodness of software engineering functions like project planning, requirements management, etc. The KPA consists of the following parameters:
Goals: Objectives to be achieved.
Commitments: The requirements that the organization should meet to ensure the claimed quality of product.
Abilities: The capabilities an organization has.
Activities: The specific tasks required to achieve KPA function.
Methods for varying implementation: It explains how the KPAs can be verified.
18 KPAs are defined by SEI and associated with different maturity levels. These are described below:
Level 1 KPAs: There is no key process area at Level 1.
Level 2 KPAs:
- Software Project Planning: Gives concrete plans for software management.
- Software Project Tracing & Oversight: Establish adequate visibility into actual process to enable the organization to take immediate corrective steps if Software performance deviates from plans.
- Requirements Management: The requirements are well specified to develop a contract between developer and customer.
- Software Subcontract Management: Select qualified software subcontractors and manage them effectively.
- Software Quality Assurance (SQA): To Assure the quality of developed product.
- Software Configuration Management (SCM): Establish & maintain integrity throughout the lifecycle of project.
Level 3 KPAs:
- Organization Process Focus (OPF): The organizations responsibility is fixed for software process activities that improve the ultimate software process capability.
- Training Program (TP): It imparts training to develop the skills and knowledge of organization staff.
- Organization Process Definition (OPD): It develops a workable set of software process to enhance cumulative long term benefit of organization by improving process performance.
- Integrated Software Management (ISM): The software management and software engineering activities are defined and a tailor made standard and software process suiting to organizations requirements is developed.
- Software Product Engineering (SPE): Well defined software engineering activities are integrated to produce correct, consistent software products effectively and efficiently.
- Inter group co-ordination (IC): To satisfy the customer’s needs effectively and efficiently, Software engineering groups are created. These groups participate actively with other groups.
- Peer reviews (PR): They remove defects from software engineering work products.
Level 4 KPAs:
- Quantitative Process Management (QP): It defines quantitative standards for software process.
- Software Quality Management (SQM): It develops quantitative understanding of the quality of Software products and achieves specific quality goals.
Level 5 KPAs:
- Defect Prevention (DP): It discovers the causes of defects and devises the techniques which prevent them from recurring.
- Technology Change Management (TCM): It continuously upgrades itself according to new tools, methods and processes.
- Process Change Management (PCM): It continually improves the software processes used in organization to improve software quality, increase productivity and decrease cycle time for product development.
















